T013 · Data acquisition from PubChem¶
Note: This talktorial is a part of TeachOpenCADD, a platform that aims to teach domain-specific skills and to provide pipeline templates as starting points for research projects.
Authors:
Jaime Rodríguez-Guerra, 2019-2020, Volkamer lab, Charité
Dominique Sydow, 2019-2020, Volkamer lab, Charité
Yonghui Chen, 2019-2020, Volkamer lab, Charité
Aim of this talktorial¶
In this notebook, you will learn how to search for compounds similar to an input SMILES in PubChem with the API web service.
Contents in Theory¶
PubChem
Programmatic access to PubChem
Contents in Practical¶
Simple examples for the PubChem API
How to get the PubChem CID for a compound
Retrieve molecular properties based on a PubChem CID
Depict a compound with PubChem
Query PubChem for similar compounds
Determine a query compound
Create task and get the job key
Download results when job finished
Get canonical SMILES for resulting molecules
Show the results
References¶
Literature:
PubChem 2019 update: Nucleic Acids Res. (2019), 47, D1102-1109
PubChem in 2021: Nucleic Acids Res.(2021), 49, D1388–D1395
Documentation:
[1]:
import sys
if "google.colab" in sys.modules:
%pip install teachopencadd --no-deps -q
!teachopencadd -d 13
%pip uninstall teachopencadd -y -q
%pip install -qr requirements.txt
Theory¶
PubChem¶
PubChem is an open database containing chemical molecules and their measured activities against biological assays, maintained by the National Center for Biotechnology Information (NCBI), part of National Institutes of Health (NIH). It is the world’s largest freely available database of chemical information, collected from more than 770 data sources. There are three dynamically growing primary subdatabases, i.e., substances, compounds, and bioassay databases. As of August 2020, PubChem contains over 110 million unique chemical structures and over 270 million bioactivities (Nucleic Acids Res.(2021), 49, D1388–D1395).
These compounds can be queried using a broad range of properties including chemical structure, name, fragments, chemical formula, molecular weight, XlogP, hydrogen bond donor and acceptor count, etc. There is no doubt that PubChem has become a key chemical information resource for scientists, students, and the general public.
Every data from PubChem is free to access through both the web interface and a programmatic interface. Here, we are going to learn how to use the API of PubChem to do some cool things.
Programmatic access to PubChem¶
For some reasons, mainly historical, PubChem provides several ways of programmatic access to the open data.
PUG-REST is a Representational State Transfer (REST)-style version of the PUG (Power User Gateway) web service, with both the syntax of the HTTP requests and the available functions. It can also provide convenient access to information on PubChem records which are not reachable with other PUG services.
PUG-View is another REST-style web service for PubChem. It can provide full reports, including third-party textual annotation, for PubChem records.
PUG offers programmatic access to PubChem service via a single common gateway interface (CGI).
PUG-SOAP uses the simple object access protocol (SOAP) to access PubChem data.
PubChemRDF REST interface is a special interface for RDF-encoded PubChem data.
For more details about the PubChem API, please check out the introduction of programmatic access in the PubChem Docs.
In this tutorial, we will focus on the PUG-REST variant of the API, please refer to Talktorial T011 for an introduction.
Practical¶
In this section, we will discuss how to search PubChem based on a given query molecule using the PUG-REST access.
[2]:
import time
from pathlib import Path
from urllib.parse import quote
from IPython.display import Markdown, Image, HTML
import requests
import pandas as pd
from rdkit import Chem
from rdkit.Chem import PandasTools
from rdkit.Chem.Draw import MolsToGridImage
[3]:
HERE = Path(_dh[-1])
DATA = HERE / "data"
Simple examples for the PubChem API¶
Before querying PubChem for similar compounds, we provide some simple examples to show how to use the PubChem API. For more detail about the PubChem API, see PUG-REST tutorial.
How to get the PubChem CID for a compound¶
For example, we will search for the PubChem Compound Identification (CID) for Aspirin by name.
[4]:
# Get PubChem CID by name
name = "aspirin"
url = f"https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/name/{name}/cids/JSON"
r = requests.get(url)
r.raise_for_status()
response = r.json()
if "IdentifierList" in response:
cid = response["IdentifierList"]["CID"][0]
else:
raise ValueError(f"Could not find matches for compound: {name}")
print(f"PubChem CID for {name} is:\n{cid}")
# NBVAL_CHECK_OUTPUT
PubChem CID for aspirin is:
2244
Retrieve molecular properties based on a PubChem CID¶
We can get interesting properties for a compound through its PubChem CID, such as molecular weight, pKd, logP, etc. Here, we will search for the molecular weight for Aspirin.
[5]:
# Get mol weight for aspirin
url = f"https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/cid/{cid}/property/MolecularWeight/JSON"
r = requests.get(url)
r.raise_for_status()
response = r.json()
if "PropertyTable" in response:
mol_weight = response["PropertyTable"]["Properties"][0]["MolecularWeight"]
else:
raise ValueError(f"Could not find matches for PubChem CID: {cid}")
print(f"Molecular weight for {name} is:\n{mol_weight}")
# NBVAL_CHECK_OUTPUT
Molecular weight for aspirin is:
180.16
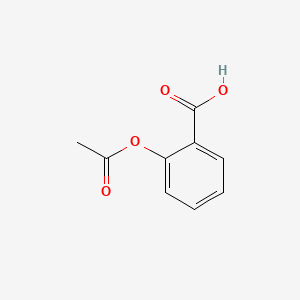
Depict a compound with PubChem¶
[6]:
# Get PNG image from PubChem
url = f"https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/cid/{cid}/PNG"
r = requests.get(url)
r.raise_for_status()
display(Markdown("The 2D structure of Aspirin:"))
display(Image(r.content))
The 2D structure of Aspirin:
Query PubChem for similar compounds¶
Use a SMILES string of a query compound to search for similar compounds in PubChem.
Tip: You can check Talktorial T001 to see how to do a similar operation with the ChEMBL database.
We define a function to query the PubChem service for similar compounds to the given one. The Tanimoto-based similarity between (2D) PubChem fingerprint will be calculated here. You can see this paper for more details about similarity evaluation in PubChem, and the PubChem fingerprint specification for the details about PubChem fingerprint.
1. Determine a query compound¶
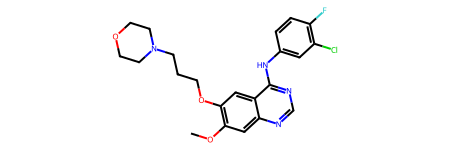
In the following steps, we will search compounds similar to Gefitinib, an inhibitor for EGFR, from the PubChem service. You can also choose another compound which you are interested in.
[7]:
query = "COC1=C(C=C2C(=C1)N=CN=C2NC3=CC(=C(C=C3)F)Cl)OCCCN4CCOCC4" # Gefitinib
print("The structure of Gefitinib:")
Chem.MolFromSmiles(query)
The structure of Gefitinib:
[7]:
2. Create task and get the job key¶
Input the canonical SMILES string for the given compound to create a new task, so we obtain a job key here. Note that this asynchronous API will not return the data immediately. In this case, the callback will be provided only when the requested resource is ready, which can be checked by the job key. So asynchronous requests are useful to work around certain slower operations.
[8]:
def query_pubchem_for_similar_compounds(smiles, threshold=75, n_records=10):
"""
Query PubChem for similar compounds and return the job key.
Parameters
----------
smiles : str
The canonical SMILES string for the given compound.
threshold : int
The threshold of similarity, default 75%. In PubChem, the default threshold is 90%.
n_records : int
The maximum number of feedback records.
Returns
-------
str
The job key from the PubChem web service.
"""
escaped_smiles = quote(smiles).replace("/", ".")
url = f"https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/similarity/smiles/{escaped_smiles}/JSON?Threshold={threshold}&MaxRecords={n_records}"
r = requests.get(url)
r.raise_for_status()
key = r.json()["Waiting"]["ListKey"]
return key
[9]:
job_key = query_pubchem_for_similar_compounds(query)
job_key
[9]:
'1817476401915959628'
3. Download results when job finished¶
Check if the job finished within the time limit. The standard time limit in PubChem is 30 seconds (we can reset it). It means that if a request is not completed within the time limit, a timeout error will be returned. So, just wait patiently for the callback.
Then download results - PubChem CIDs in this case - when the job is finished.
[10]:
def check_and_download(key, attempts=30):
"""
Check job status and download PubChem CIDs when the job finished
Parameters
----------
key : str
The job key of the PubChem service.
attempts : int
The time waiting for the feedback from the PubChem service.
Returns
-------
list
The PubChem CIDs of similar compounds.
"""
url = f"https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/listkey/{key}/cids/JSON"
print(f"Querying for job {key} at URL {url}...", end="")
while attempts:
r = requests.get(url)
r.raise_for_status()
response = r.json()
if "IdentifierList" in response:
cids = response["IdentifierList"]["CID"]
break
attempts -= 1
print(".", end="")
time.sleep(10)
else:
raise ValueError(f"Could not find matches for job key: {key}")
return cids
[11]:
similar_cids = check_and_download(job_key)
Querying for job 1817476401915959628 at URL https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/listkey/1817476401915959628/cids/JSON....
4. Get canonical SMILES for resulting molecules¶
[12]:
similar_cids
[12]:
[2092, 176870, 208908, 3081361, 3157, 4893, 5401, 5583, 123631, 68546]
[13]:
def smiles_from_pubchem_cids(cids):
"""
Get the canonical SMILES string from the PubChem CIDs.
Parameters
----------
cids : list
A list of PubChem CIDs.
Returns
-------
list
The canonical SMILES strings of the PubChem CIDs.
"""
url = f"https://pubchem.ncbi.nlm.nih.gov/rest/pug/compound/cid/{','.join(map(str, cids))}/property/CanonicalSMILES/JSON"
r = requests.get(url)
r.raise_for_status()
return [item.get("ConnectivitySMILES") for item in r.json()["PropertyTable"]["Properties"]]
[14]:
similar_smiles = smiles_from_pubchem_cids(similar_cids)
[15]:
similar_smiles
[15]:
['CN(CCCNC(=O)C1CCCO1)C2=NC3=CC(=C(C=C3C(=N2)N)OC)OC',
'COCCOC1=C(C=C2C(=C1)C(=NC=N2)NC3=CC=CC(=C3)C#C)OCCOC',
'CS(=O)(=O)CCNCC1=CC=C(O1)C2=CC3=C(C=C2)N=CN=C3NC4=CC(=C(C=C4)OCC5=CC(=CC=C5)F)Cl',
'CN1CCC(CC1)COC2=C(C=C3C(=C2)N=CN=C3NC4=C(C=C(C=C4)Br)F)OC',
'COC1=C(C=C2C(=C1)C(=NC(=N2)N3CCN(CC3)C(=O)C4COC5=CC=CC=C5O4)N)OC',
'COC1=C(C=C2C(=C1)C(=NC(=N2)N3CCN(CC3)C(=O)C4=CC=CO4)N)OC',
'COC1=C(C=C2C(=C1)C(=NC(=N2)N3CCN(CC3)C(=O)C4CCCO4)N)OC',
'CC1=C(C=CC2=C1C(=NC(=N2)N)N)CNC3=CC(=C(C(=C3)OC)OC)OC',
'COC1=C(C=C2C(=C1)N=CN=C2NC3=CC(=C(C=C3)F)Cl)OCCCN4CCOCC4',
'COC1=C(C=C2C(=C1)C(=NC(=N2)N3CCN(CC3)C(=O)C4=CC=CO4)N)OC.Cl']
Then, we create the RDKit molecules and depict them.
[16]:
query_results_df = pd.DataFrame({"smiles": similar_smiles, "CIDs": similar_cids})
# 2. FIX: Filter the DataFrame to remove any rows where the 'smiles' value is None.
# This prevents RDKit from trying to process an invalid input.
query_results_df.dropna(subset=["smiles"], inplace=True)
PandasTools.AddMoleculeColumnToFrame(query_results_df, smilesCol="smiles")
query_results_df.head(5)
[16]:
| smiles | CIDs | ROMol | |
|---|---|---|---|
| 0 | CN(CCCNC(=O)C1CCCO1)C2=NC3=CC(=C(C=C3C(=N2)N)O... | 2092 | <rdkit.Chem.rdchem.Mol object at 0x7f1d89874dd0> |
| 1 | COCCOC1=C(C=C2C(=C1)C(=NC=N2)NC3=CC=CC(=C3)C#C... | 176870 | <rdkit.Chem.rdchem.Mol object at 0x7f1d89874ba0> |
| 2 | CS(=O)(=O)CCNCC1=CC=C(O1)C2=CC3=C(C=C2)N=CN=C3... | 208908 | <rdkit.Chem.rdchem.Mol object at 0x7f1d89875000> |
| 3 | CN1CCC(CC1)COC2=C(C=C3C(=C2)N=CN=C3NC4=C(C=C(C... | 3081361 | <rdkit.Chem.rdchem.Mol object at 0x7f1d89874f90> |
| 4 | COC1=C(C=C2C(=C1)C(=NC(=N2)N3CCN(CC3)C(=O)C4CO... | 3157 | <rdkit.Chem.rdchem.Mol object at 0x7f1d89874b30> |
[17]:
query_results_df
[17]:
| smiles | CIDs | ROMol | |
|---|---|---|---|
| 0 | CN(CCCNC(=O)C1CCCO1)C2=NC3=CC(=C(C=C3C(=N2)N)O... | 2092 |  |
| 1 | COCCOC1=C(C=C2C(=C1)C(=NC=N2)NC3=CC=CC(=C3)C#C... | 176870 |  |
| 2 | CS(=O)(=O)CCNCC1=CC=C(O1)C2=CC3=C(C=C2)N=CN=C3... | 208908 |  |
| 3 | CN1CCC(CC1)COC2=C(C=C3C(=C2)N=CN=C3NC4=C(C=C(C... | 3081361 |  |
| 4 | COC1=C(C=C2C(=C1)C(=NC(=N2)N3CCN(CC3)C(=O)C4CO... | 3157 |  |
| 5 | COC1=C(C=C2C(=C1)C(=NC(=N2)N3CCN(CC3)C(=O)C4=C... | 4893 |  |
| 6 | COC1=C(C=C2C(=C1)C(=NC(=N2)N3CCN(CC3)C(=O)C4CC... | 5401 |  |
| 7 | CC1=C(C=CC2=C1C(=NC(=N2)N)N)CNC3=CC(=C(C(=C3)O... | 5583 |  |
| 8 | COC1=C(C=C2C(=C1)N=CN=C2NC3=CC(=C(C=C3)F)Cl)OC... | 123631 |  |
| 9 | COC1=C(C=C2C(=C1)C(=NC(=N2)N3CCN(CC3)C(=O)C4=C... | 68546 |  |
5. Show the results¶
Show the compounds with images using RDKit’s drawing functions.
[18]:
def multi_preview_smiles(query_smiles, query_name, similar_molecules_pd):
"""
Show query and similar compounds in 2D structure representation.
Parameters
----------
query_smiles : str
The SMILES string of query compound.
query_name : str
The name of query compound.
similar_molecules_pd : pandas
The pandas DataFrame which contains the SMILES string and CIDs of similar molecules.
Returns
-------
MolsToGridImage
"""
# Handle the case where the input DataFrame is empty (e.g., all CIDs failed).
if similar_molecules_pd.empty:
return HTML(
f"<p style='color:red;'>No similar compounds were successfully retrieved. Cannot generate image.</p>"
)
# Proceed only if the DataFrame is not empty
legends = [f"PubChem CID: {str(s)}" for s in similar_molecules_pd["CIDs"].tolist()]
# Filter out any None values
molecules = [Chem.MolFromSmiles(s) for s in similar_molecules_pd["smiles"]]
molecules = [mol for mol in molecules if mol is not None]
# Check if the query molecule can be drawn
if not molecules and len(similar_molecules_pd) > 0:
print("Note: The list of similar compounds resulted in no valid RDKit molecules.")
query_mol = Chem.MolFromSmiles(query_smiles)
# include the query molecule.
# Total molecules to be drawn is len(molecules) + 1 (the query molecule).
total_mols = len(molecules) + 1
return MolsToGridImage(
[query_mol] + molecules,
molsPerRow=3,
subImgSize=(300, 300),
maxMols=total_mols, # Corrected from len(molecules)
legends=([query_name] + legends),
useSVG=True,
)
[19]:
print("The results of querying similar compounds for Gefitinib:")
img = multi_preview_smiles(query, "Gefitinib", query_results_df)
img
The results of querying similar compounds for Gefitinib:
[19]:

Discussion¶
In this notebook, you have learned how to access and search similar compounds from the PubChem database via the PUG-REST programmatic access. Is it convenient? PUG-REST can do more than that. See PUG-REST to get more power!
Quiz¶
Can you make the similarity search more strict?
Is any of the proposed candidates already an approved inhibitor? (Hint: You can scrape PKIDB and check against the list of SMILES, also see Talktorial T011)
Can you try to reuse the functions in this notebook so search for similar compounds to Imatinib and inspect your results?
[ ]: