T015 · Protein ligand docking¶
Note: This talktorial is a part of TeachOpenCADD, a platform that aims to teach domain-specific skills and to provide pipeline templates as starting points for research projects.
Authors:
Jaime Rodríguez-Guerra, 2019-20, Volkamer lab, Charité
Dominique Sydow, 2019-20, Volkamer lab, Charité
Michele Wichmann, 2019-20, student work at Volkamer lab, Charité
Maria Trofimova, CADD seminar, 2020, Charité/FU Berlin
David Schaller, 2020-21, Volkamer lab, Charité
Andrea Volkamer, 2021, Volkamer lab, Charité
Aim of this talktorial¶
In this talktorial, we will use molecular docking to predict the binding mode of a small molecule in a protein binding site. The epidermal growth factor receptor (EGFR) will serve as a model system to explain important steps of a molecular docking workflow with the docking software Smina, a fork of Autodock Vina.
Contents in Theory¶
Molecular docking
Sampling algorithms
Scoring functions
Limitations
Visual inspection
Docking software
Commercial
Free (for academics)
Contents in Practical¶
Preparation of protein and ligand
Binding site definition
Docking calculation
Docking results visualization
References¶
Molecular docking:
Pagadala et al., Biophy Rev (2017), 9, 91-102
Meng et al., Curr Comput Aided Drug Des (2011), 7, 2, 146-157
Gromski et al., Nat Rev Chem (2019), 3, 119-128
Docking and scoring function assessment:
Warren et al., J Med Chem (2006), 49, 20, 5912-31
Wang et al., Phys Chem Chem Phys (2016), 18, 18, 12964-75
Koes et al., J Chem Inf Model (2013), 53, 8, 1893-1904
Kimber et al., Int J Mol Sci, (2021), 22, 9, 1-34
McNutt et al., J Cheminform (2021), 13, 43, 13-43
Visual inspection of docking results: Fischer et al., J Med Chem (2021), 64, 5, 2489–2500
Tools used
[1]:
import sys
if "google.colab" in sys.modules:
%pip install teachopencadd --no-deps -q
!teachopencadd -d 15
%pip uninstall teachopencadd -y -q
%pip install -qr requirements.txt
%conda install openbabel smina -y -c conda-forge
Theory¶
Molecular docking¶
In the modern drug discovery pipeline, determining the binding mode of an active molecule to a given protein target is of utmost importance. Such information can suggest novel chemical modifications to optimize interactions between ligand and protein, thus, increasing the binding affinity. Molecular docking software can predict these binding modes by sampling possible conformations of a ligand inside the protein binding pocket (Fig. 1). A scoring function is thereby used to estimate the quality of each binding pose, which is commonly calculated with a variety of terms for different non-covalent molecular interactions; e.g. electrostatics and van der Waals energies (Biophy Rev (2017), 9, 91-102).
Also, improvements in the fields of cheminformatics and machine learning lead to the development of algorithms able to generate libraries with billions of theoretically synthesizable molecules (Nat Rev Chem (2019), 3, 119-128). Molecular docking can probe and (de)prioritize these molecules before they are even synthesized, thus, accelerate the discovery of novel lead candidates.
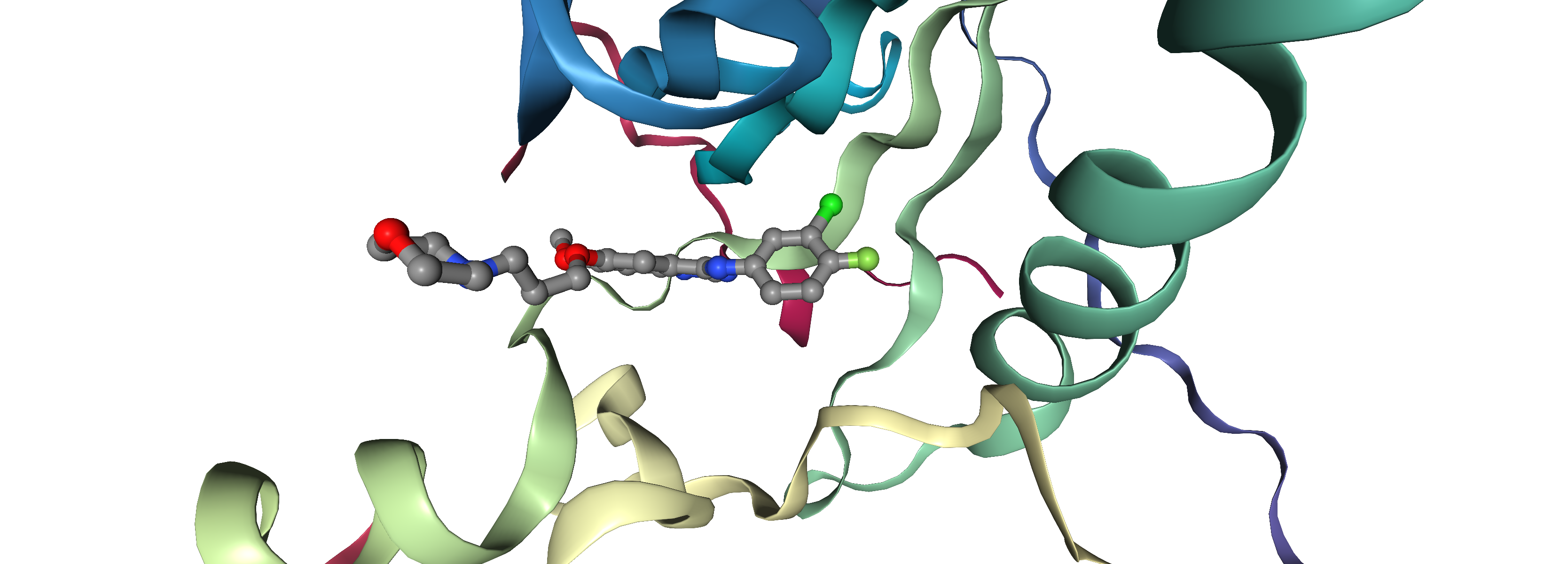
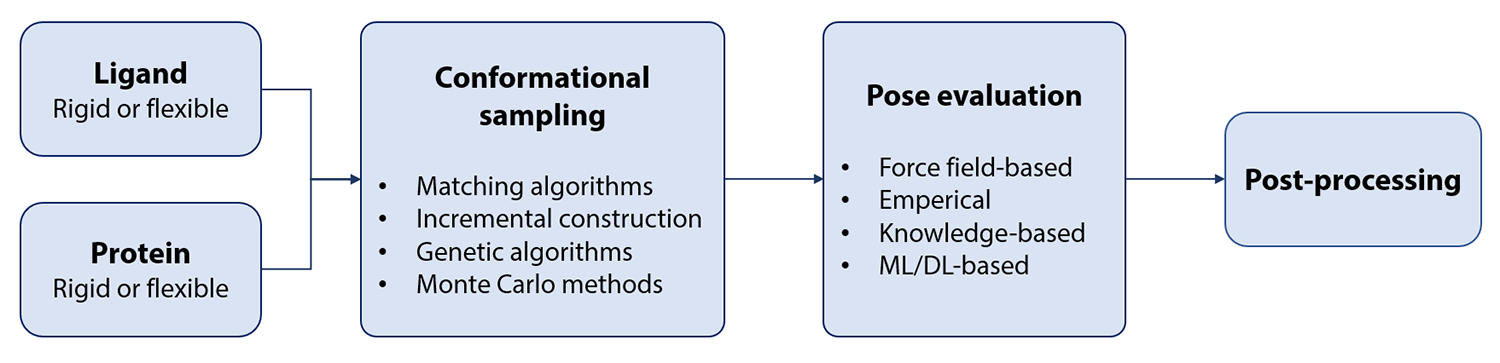
A molecular docking workflow usually involves the following steps (Fig. 2):
Input file preparation, e.g. protonation and conversion into specific file formats
Conformational sampling of the ligand inside the binding pocket
Scoring of the generated docking poses
Post-processing, e.g. storing a diverse and highly scored set of docking poses for further analysis
Sampling algorithms¶
Most of the currently available molecular docking tools use one or more of the following algorithms to sample the conformations of ligands inside a protein binding pocket (Curr Comput Aided Drug Des (2011), 7, 2, 146-157).
Matching algorithms (MA) compare the shape similarity of ligand conformations and the protein binding pocket, which usually also includes chemical information, e.g. hydrogen bond acceptors and donors. Programs using MA for sampling conformations belong usually to the fastest docking programs. However, these programs require a prior computation of ligand conformations that are used during shape comparison. If the biologically relevant conformation is not present in this library, the algorithm will fail.
In the incremental instruction method, the ligand is first deconstructed into smaller fragments by breaking its rotatable bonds. One of the fragments, for example the biggest one, is placed first into the binding pocket. Subsequently, the complete ligand is incrementally constructed inside the binding pocket by connecting the remaining fragments at the appropriate positions of the core fragment. Incremental construction belongs to the fastest class of algorithms but is limited to medium-sized ligands, since an increasing number of fragments can lead to a combinatorial explosion that can extremely slow down the docking calculation.
Stochastic methods sample ligand conformations by rigid-body rotation and translation as well as bond rotation.
Monte Carlo methods generate random placements and evaluate obtained conformations inside the protein binding pocket with an energy-based selection criterion. If the pose passes a certain threshold, the conformation is saved and subsequently randomly modified to generate another conformation. This process is performed until a pre-defined number of conformations is reached.
Genetic algorithms are inspired by the natural selection concepts borrowed from Darwin’s Theory of evolution. Geometric properties of a ligand pose are thereby stored on so-called chromosomes, which define the conformation of the ligand. Genetic operations like mutation and cross-over are used to sample the conformational space of the ligand. A scoring function is then used to estimate the quality of the conformations inside the binding pocket. Populations with genetic alterations with the highest scores are finally used for a new generation, which resembles Darwin’s concept of the survival of the fittest.
Scoring functions¶
Scoring functions are used to discriminate correct from incorrect docking poses, i.e., to prioritize active over inactive molecules. They need to be as accurate as possible, and at the same time should require little computing time. Thus, they involve many assumptions and simplifications to reduce computational costs (Curr Comput Aided Drug Des (2011), 7, 2, 146-157, Int J Mol Sci, (2021), 22, 9, 1-34, J Cheminform (2021), 13, 43, 13-43).
Force field-based scoring functions estimate the binding energy by calculating the strength of non-bonded interactions (e.g. van der Waals force, electrostatic interactions) of the protein-ligand complex. Extensions of these methods also include estimates for entropy and desolvation penalties upon ligand binding. A disadvantage of these scoring functions is their comparably high computational cost.
Empirical scoring functions are based on coefficients that are used to estimate the contributions of different interaction types, e.g., hydrogen bonds, ionic interactions, hydrophobic contacts. These coefficients were obtained from a regression analysis of protein-ligand complexes with known binding affinity.
Knowledge-based scoring functions integrate results from a statistical analysis of experimentally resolved protein-ligand complexes, which gathered information about interatomic contact frequencies and distances observed between protein and ligand. Docking poses will be scored higher if they show contact characteristics that were often observed in the statistical analysis.
ML/DL-based scoring functions are machine learning (ML)/deep learning (DL) models that were trained on a set of available protein-ligand complexes with known binding affinity. The protein-ligand complexes are thereby encoded in a computer-readable format, e.g. as interaction fingerprints or graph. Such scoring functions can be applied during post-processing to rank hit compounds more accurately or during the pose evaluation step.
ℹ Tip: Check these training videos by Schroedinger for a visual refresher on drug-target interactions and protein-ligand docking.
Limitations¶
Docking programs can consider some residue sidechains flexible during docking calculations to account for binding pocket flexibility. However, the dynamic, adaptive nature of the protein-ligand binding is insufficiently explored by protein-ligand docking. This can result in false positives: Even if the ligand finds a suitable pose in the binding pocket, this position is not guaranteed until the protein is allowed to explore near-minima conformations. Hence, short molecular dynamics simulations are nowadays recommended to evaluate the stability of the predicted pinding pose (Curr Comput Aided Drug Des (2011), 7, 2, 146-157).
Scoring functions used by docking programs must be cheap to compute. While the accuracy is good enough to distinguish good poses from bad poses, it can have problems sorting the best poses. For example, while most popular docking programs are able to find the experimental pose in their calculations, this pose is rarely the best one of the proposed set. Furthermore, several retrospective studies have shown that docking scores often poorly correlate with binding affinity (J Med Chem (2006), 49, 20, 5912-31, Phys Chem Chem Phys (2016), 18, 18, 12964-75).
To reduce the computational cost, docking procedures are only performed in a subset of the protein (normally around a known binding pocket). Choosing the correct binding site can become another challenge, if the binding pocket is not known a priori.
To maximize the accuracy of the calculation, the ligand and protein structures must be prepared appropriately. Protonation states of amino acids and the ligands can be tricky to get right, especially in the case of (potential) tautomers. This introduces yet another cause to obtain unfavorable results.
Visual inspection¶
Due to the afore mentioned limitations of sampling algorithms and docking scoring functions, a visual inspection is commonly performed in most docking scenarios. Interestingly, a survey revealed that molecular modeling experts find docking scores to be the least important criterion for selecting docking poses (J Med Chem (2021), 64, 5, 2489–2500). Instead, the following criteria are used when selecting docking poses:
Similarity to binding modes observed in available crystal structures of the protein of interest
Steric as well as electrostatic and hydrophobic complementary of ligand and protein
Unsatisfied hydrogen bond donor and acceptor groups in ligand and protein
Solvent exposed hydrophobic ligand moieties
Interactions with side chains or metal ions critical for protein function, e.g., enzymatic activity
Interaction partners and localization of hydrogen bonds
Hydrogen bonds formed with the protein backbone in an enclosed hydrophobic protein environment are considered more favorable
Hydrogen bonds with charged and solvent exposed protein side chains are considered less favorable
Displacement of or interactions with water molecules in the binding pocket
Protein and ligand strain induced by ligand binding
However, also the visual inspection of docking poses has considerable limitations. Of course the success of visual inspection strongly depends on the experience and intuition of the participating scientists. Also, visual inspection can only be performed for a rather small number of molecules considering the available chemical space in virtual screening. Hence, visual inspection is often restricted to the highest scoring molecules of a virtual screening pipeline or only performed for a smaller set of ligands, in which scientists are particularly interested. Finally, also the best expert cannot pick the correct binding pose if it was not sampled by the docking program.
Docking software¶
In the following, several docking programs are exemplary listed and categorized according to the availability of free licenses. A more comprehensive list can be found at Wikipedia.
Commercial
Free (for academics)
Practical¶
In this talktorial, we will use the docking software Smina to re-dock a co-crystallized ligand into the protein binding pocket of EGFR.
Smina (J Chem Inf Model (2013), 53, 8, 1893-1904) belongs to the AutoDock family of docking software that requires preparation of protein and ligand prior to docking.
After docking, results will be analyzed for the deviation from the crystal structure.
[3]:
# import libraries
import warnings
from pathlib import Path
import subprocess
import nglview as nv
from openbabel import pybel
from opencadd.structure.core import Structure
[4]:
# filter warnings
warnings.filterwarnings("ignore")
ob_log_handler = pybel.ob.OBMessageHandler()
pybel.ob.obErrorLog.SetOutputLevel(0)
[5]:
# define paths
HERE = Path(_dh[-1])
DATA = HERE / "data"
Preparation of protein and ligand¶
Programs based on the AutoDock software require protein and ligand to be prepared in PDBQT format. This file format is very similar to the PDB format but additionally stores information about the atom type and partial charges. Luckily, the OpenBabel package provides this functionality. First, we will retrieve a protein-ligand complex of EGFR (2ITO) from the Protein Data Bank, save the protein as PDB file and convert it to
PDBQT format using OpenBabel.
[6]:
# retrieve structure from the Protein Data Bank
pdb_id = "2ito"
structure = Structure.from_pdbid(pdb_id)
# element information maybe missing, but important for subsequent PDBQT conversion
if not hasattr(structure.atoms, "elements"):
structure.add_TopologyAttr("elements", structure.atoms.types)
structure
# NBVAL_CHECK_OUTPUT
[6]:
<Universe with 2484 atoms>
Prepare protein
[7]:
# write the protein file to disk
protein = structure.select_atoms("protein")
protein.write(DATA / "protein.pdb")
[8]:
def pdb_to_pdbqt(pdb_path, pdbqt_path, pH=7.4):
"""
Convert a PDB file to a PDBQT file needed by docking programs of the AutoDock family.
Parameters
----------
pdb_path: str or pathlib.Path
Path to input PDB file.
pdbqt_path: str or pathlib.path
Path to output PDBQT file.
pH: float
Protonation at given pH.
"""
molecule = list(pybel.readfile("pdb", str(pdb_path)))[0]
# add hydrogens at given pH
molecule.OBMol.CorrectForPH(pH)
molecule.addh()
# add partial charges to each atom
for atom in molecule.atoms:
atom.OBAtom.GetPartialCharge()
molecule.write("pdbqt", str(pdbqt_path), overwrite=True)
return
[9]:
# convert protein to PDBQT format
pdb_to_pdbqt(DATA / "protein.pdb", DATA / "protein.pdbqt")
Prepare ligand
Next, we will take care of the ligand preparation. Since we want to re-dock the co-crystallized ligand into the binding site, we can retrieve the ligand in SMILES format directly from the Protein Data Bank (ligand id: IRE). Again, we will use OpenBabel to generate the PDBQT file (including the generation of a 3D conformation).
[10]:
# define ligand SMILES for protein-ligand complex of interest
smiles = "COC1=C(C=C2C(=C1)N=CN=C2NC3=CC(=C(C=C3)F)Cl)OCCCN4CCOCC4"
[11]:
def smiles_to_pdbqt(smiles, pdbqt_path, pH=7.4):
"""
Convert a SMILES string to a PDBQT file needed by docking programs of the AutoDock family.
Parameters
----------
smiles: str
SMILES string.
pdbqt_path: str or pathlib.path
Path to output PDBQT file.
pH: float
Protonation at given pH.
"""
molecule = pybel.readstring("smi", smiles)
# add hydrogens at given pH
molecule.OBMol.CorrectForPH(pH)
molecule.addh()
# generate 3D coordinates
molecule.make3D(forcefield="mmff94s", steps=10000)
# add partial charges to each atom
for atom in molecule.atoms:
atom.OBAtom.GetPartialCharge()
molecule.write("pdbqt", str(pdbqt_path), overwrite=True)
return
[12]:
# convert the ligand into PDBQT format
smiles_to_pdbqt(smiles, DATA / "ligand.pdbqt")
Binding site definition¶
In theory, it would be possible to perform a docking calculation considering the whole protein as binding site. However, due to the known limitations of docking algorithms, it is always recommended to restrict the binding site to a certain region of interest to increase performance and accuracy. Here, we can use the coordinates of the co-crystallized ligand to define the binding site with a rectangular box.
We will calculate the geometric center of the molecule, which represents the center of the rectangular box,
as well as the length of the molecule in each dimension, which corresponds to the edge lengths of the rectangular box.
Also, we will add a 5 Å buffer in each dimension to allow the correct placements of ligands that are bigger than the co-crystallized ligands or bind in a different fashion.
If no co-crystallized ligand is available, one can also use binding site detection algorithms to identify regions of interest for docking (see Talktorial T014 on binding site detection algorithms).
[13]:
ligand_resname = "IRE"
ligand = structure.select_atoms(f"resname {ligand_resname}")
pocket_center = (ligand.positions.max(axis=0) + ligand.positions.min(axis=0)) / 2
pocket_size = ligand.positions.max(axis=0) - ligand.positions.min(axis=0) + 5
Docking calculation¶
Finally, we can proceed to the actual docking calculation. Smina is a command line tool, which currently does not provide a Python API.
However, we can write a function that will take care of generating the proper command and execute the calculation.
Besides providing the ligand, protein and pocket information, we can also alter the behavior of the docking calculation by setting the number of docking poses to be generated and by changing the exhaustiveness, which controls the number of independent docking calculations.
Note: Depending on the CPU speed and the docking settings this step may take a few minutes.
[14]:
def run_smina(
ligand_path, protein_path, out_path, pocket_center, pocket_size, num_poses=10, exhaustiveness=8
):
"""
Perform docking with Smina.
Parameters
----------
ligand_path: str or pathlib.Path
Path to ligand PDBQT file that should be docked.
protein_path: str or pathlib.Path
Path to protein PDBQT file that should be docked to.
out_path: str or pathlib.Path
Path to which docking poses should be saved, SDF or PDB format.
pocket_center: iterable of float or int
Coordinates defining the center of the binding site.
pocket_size: iterable of float or int
Lengths of edges defining the binding site.
num_poses: int
Maximum number of poses to generate.
exhaustiveness: int
Accuracy of docking calculations.
Returns
-------
output_text: str
The output of the Smina calculation.
"""
output_text = subprocess.check_output(
[
"smina",
"--ligand",
str(ligand_path),
"--receptor",
str(protein_path),
"--out",
str(out_path),
"--center_x",
str(pocket_center[0]),
"--center_y",
str(pocket_center[1]),
"--center_z",
str(pocket_center[2]),
"--size_x",
str(pocket_size[0]),
"--size_y",
str(pocket_size[1]),
"--size_z",
str(pocket_size[2]),
"--num_modes",
str(num_poses),
"--exhaustiveness",
str(exhaustiveness),
],
universal_newlines=True, # needed to capture output text
)
return output_text
[15]:
output_text = run_smina(
DATA / "ligand.pdbqt",
DATA / "protein.pdbqt",
DATA / "docking_poses.sdf",
pocket_center,
pocket_size,
)
print(output_text)
_______ _______ _________ _ _______
( ____ \( )\__ __/( ( /|( ___ )
| ( \/| () () | ) ( | \ ( || ( ) |
| (_____ | || || | | | | \ | || (___) |
(_____ )| |(_)| | | | | (\ \) || ___ |
) || | | | | | | | \ || ( ) |
/\____) || ) ( |___) (___| ) \ || ) ( |
\_______)|/ \|\_______/|/ )_)|/ \|
smina is based off AutoDock Vina. Please cite appropriately.
Weights Terms
-0.035579 gauss(o=0,_w=0.5,_c=8)
-0.005156 gauss(o=3,_w=2,_c=8)
0.840245 repulsion(o=0,_c=8)
-0.035069 hydrophobic(g=0.5,_b=1.5,_c=8)
-0.587439 non_dir_h_bond(g=-0.7,_b=0,_c=8)
1.923 num_tors_div
Using random seed: 480438074
0% 10 20 30 40 50 60 70 80 90 100%
|----|----|----|----|----|----|----|----|----|----|
***************************************************
mode | affinity | dist from best mode
| (kcal/mol) | rmsd l.b.| rmsd u.b.
-----+------------+----------+----------
1 -8.6 0.000 0.000
2 -8.6 1.051 1.363
3 -8.3 1.766 3.351
4 -8.2 1.228 1.750
5 -7.7 4.330 7.128
6 -7.5 4.542 7.289
7 -7.5 2.231 5.243
8 -7.5 3.920 6.712
9 -7.4 3.261 4.616
10 -7.0 4.291 7.330
Refine time 24.395
Loop time 25.464
The output is a file containing the docking poses and a text based description of the docking results including an estimated affinity and the root mean square deviation (RMSD) of each pose from the pose with the highest predicted affinity (Vina output description).
Let’s also check if the output files were generated.
[16]:
(DATA / "docking_poses.sdf").exists()
# NBVAL_CHECK_OUTPUT
[16]:
True
Docking results visualization¶
Now, let us analyze the docking results. Were we able to reproduce the binding mode observed in the experimentally resolved structure?
Several binding poses were generated and saved as a single SDF file. To allow a more clear visualization with NGLView, we will split the SDF file and save each docking pose in a separate file.
[17]:
def split_sdf_file(sdf_path):
"""
Split an SDF file into seperate files for each molecule.
Each file is named with consecutive numbers.
Parameters
----------
sdf_path: str or pathlib.Path
Path to SDF file that should be split.
"""
sdf_path = Path(sdf_path)
stem = sdf_path.stem
parent = sdf_path.parent
molecules = pybel.readfile("sdf", str(sdf_path))
for i, molecule in enumerate(molecules, 1):
molecule.write("sdf", str(parent / f"{stem}_{i}.sdf"), overwrite=True)
return
[18]:
split_sdf_file(DATA / "docking_poses.sdf")
In the next cell, we can visualize each docking pose separately and compare it to the binding mode observed in the X-ray structure. You can also provide the SDF file with all ligands to visualize them all together. The co-crystallized ligand is depicted with ball and sticks, the docking pose as licorice.
[19]:
docking_pose_id = 1
view = nv.show_structure_file(
str(DATA / f"docking_poses_{docking_pose_id}.sdf"),
representations=[{"params": {}, "type": "licorice"}],
)
view.add_pdbid(pdb_id)
view
[20]:
view.render_image(trim=True, factor=2);
[22]:
view._display_image()
[22]:
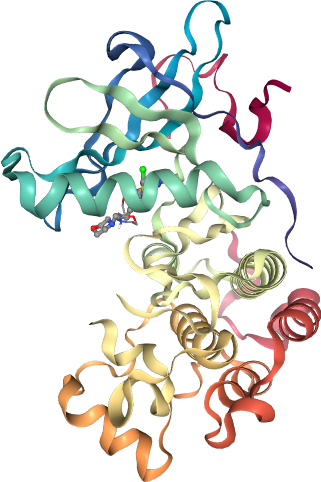
With the provided visualization you can now check if the docking program was able to recapitulate the binding pose observed in the X-ray structure. Also, you can check if the docking pose with the best score (docking_pose_id = 1) is closer to the X-ray structue then the docking pose with worst score (docking_pose_id = 10).
Discussion¶
Quiz¶
Try to increase the accuracy of the docking calculation via the exhaustiveness parameter. Do you see any improvement? What is the effect on the computational time needed?
Search the Protein Data Bank for another protein-ligand complex and try to reproduce it (re-docking).
Smina provides many more command line options (documentation on sourceforge). Are you able to implement a function that will score the binding pose observed in the X-ray structure? Is the score better or worse than your best scored docking pose?