T037 · Uncertainty estimation¶
Note: This talktorial is a part of TeachOpenCADD, a platform that aims to teach domain-specific skills and to provide pipeline templates as starting points for research projects.
Authors:
Michael Backenköhler, 2022, Volkamer lab, NextAID project, Saarland University
The predictive setting (and the model class) used in this talktorial is adapted from Talktorial T022.
Aim of this talktorial¶
Researchers often focus on prediction quality alone. However, when applying a predictive model, researchers are also interested in how certain they can be in a specific prediction. Estimating and providing such information is the goal of uncertainty estimation. In this talktorial, we discuss some common methodologies and showcase ensemble methods in practice.
Contents in Theory¶
Why a model can’t and shouldn’t be certain
Calibration
Methods overview
Single deterministic methods
Ensemble methods
Test-time data augmentation
Contents in Practical¶
Data
Model
Training
Evaluation
Ensembles - Training a model multiple times
Coverage of confidence intervals
Calibration
Ranking-based evaluation
Bagging ensemble - Training a model with varying data
Ranking-based evaluation
Test-time data augmentation
References¶
Talktorial T022
[1]:
import sys
if "google.colab" in sys.modules:
%pip install teachopencadd --no-deps -q
!teachopencadd -d 37
%pip uninstall teachopencadd -y -q
%pip install -qr requirements.txt
Theory¶
Often researchers pay a lot of attention to the quality of the estimation overall. But to apply any predictive method in practice, it is arguably as important to know how much to trust an estimation. It would be therefore nice to have not only a point estimate of something but also some indication of how certain we can be about the given estimate. The certainty is often modeled by replacing the point estimate with a distributional estimate. For example, a model \(f\) on an input does not only predict \(f(x)=\hat\theta\) but a normal distribution \(f(x)=N(\hat\theta, \hat\sigma)\).
Why a model can’t and shouldn’t be certain¶
Before discussing how to estimate uncertainty, we take a look at the causes of uncertainty. Concerning the data, there are two classes of uncertainty we can distinguish.
Aleatoric or data uncertainty is inherent in the data and its source
Epistemic is caused by the limitations of the model
Aleatoric uncertainty is unavoidable because it is inherent in the real system and the way we collect data. It is uncertainty that remains even if one can select infinitely large sets of data. Imagine you are performing a chemical experiment to determine the binding affinity between some compound and a protein. Even if you are an outstandingly careful chemist you will probably not be able to exactly reproduce the same \(K_d\) each time around. This uncertainty will always be present in the data. Even if you repeat the experiment until you reach old age.
Epistemic uncertainty is reducible uncertainty. This is the uncertainty we can get rid of by collecting more data or improvement of the model. Oftentimes this is also referred to as model uncertainty. No machine learning model is perfect. We always introduce some degree of simplification and abstraction. And this introduces uncertainty into our predictions that we will keep even given perfect data. Let’s consider again the binding affinity prediction from above. If we only consider molecules built using the same scaffold, the model cannot learn outside this domain. Therefore it is likely very uncertain for molecules based on other scaffolds. However, given data on other scaffolds the model can learn and consequently, the uncertainty reduces.
Another aspect of uncertainty is the domain of training and test data. There is in-domain uncertainty, as the uncertainty of test samples which should be “approximately” covered by training samples. Out-of-domain and domain-shift uncertainty stem from test data that is not well represented by the training data. Determining in- and out-of-domain for a given sample is a difficult problem in most domains since a good understanding of the problem is necessary to determine whether a sample is in the training domain. This problem is especially difficult in cheminformatics, where similarity metrics may fail due to activity cliffs. At activity cliffs, molecules may be very similar by metrics such as their fingerprint, but the target property differs drastically.
Calibration¶
Assume we have a machine learning model that incorporates uncertainty. How do we evaluate and improve the predicted uncertainty? This is where calibration enters the picture. Calibration deals with the accuracy of confidence given by an uncertainty estimation. For example, a well-calibrated estimation should yield a 30%-confidence interval which should, in the limit, actually cover the true value with probability \(0.3\). Oftentimes, neural network models tend to be over-confident.
There are many methods to deal with the calibration of an estimator. Among the most straightforward is to adjust predicted uncertainties after the training. To this end, we can use a held-out calibration set. This set is meant to adjust the predicted uncertainties. In an over-confident model, for example, it should lead to an increase in the predicted uncertainty. In the practical section, we demonstrate simple scaling using a calibration set.
Methods overview¶
There is a wide variety of methods providing uncertainty estimates. An excellent survey is given by Gawlikowski et al. Here, we stick with the most common and widely applicable methods. These - on the model side - can roughly be divided into
single deterministic methods and
ensemble methods.
A model-independent method is test-time data augmentation.
Single deterministic methods¶
Arguably the most straightforward method to predict uncertainty along with the point predictor. Often this amounts to the prediction of a distribution instead of a point estimate. Consider as an example the prediction of a mean and variance parameter of a normal distribution in a regression setting. In a classification setting, we often predict class probabilities, which already is an uncertainty prediction, albeit with some constraints (see Gawlikowski et al.).
Another approach is the direct prediction of uncertainty. In this case, a secondary model is trained to predict uncertainty for an already trained model. This has the obvious advantage of not needing any modification to the predictive model itself.
Ensemble methods¶
Ensemble methods build on the idea of creating a selection, i.e. an ensemble, of similar but different models. As a simple example of such an ensemble, consider a neural network model that is trained multiple times with varying random seeds. Due to the inherent randomness in the stochastic gradient descent, each trained version of the model will differ from the others.
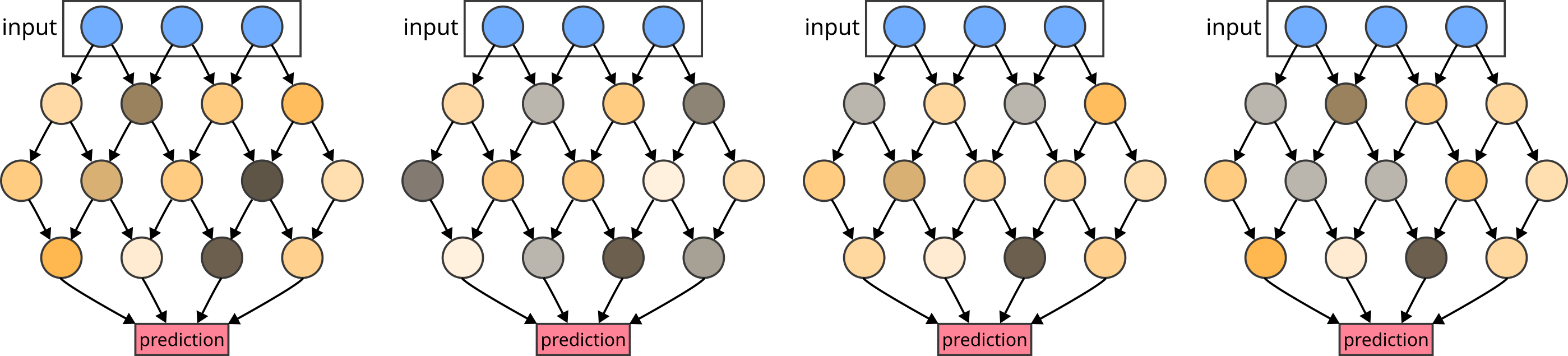
Figure 1: An ensemble of similar models with different weights obtained by multiple varying training runs.
This difference in the model parameters leads to a variety in the predicted values between all ensemble members. This variance can be used as an uncertainty estimate. As we will see in the practical section below, the variety in such an ensemble may often be insufficient. Often, the variety in such ensembles is too small and consequently, the uncertainty is underestimated.
Additional variety can be introduced into the ensemble by varying the training data for each training run. A simple way showcased below is bagging which is a shorthand for bootstrap and aggregation. There, for each training run, the training data is resampled with replacement leading to add variety in the resulting ensemble.
We can also modify the test data for uncertainty estimation. On this side, the test data can be augmented by including slightly modified versions of the input data. Note, however, that one has to be careful with the exact methods of such modifications. Especially in chemistry, even seemingly small changes such as adding or removing a bond may have large consequences. This means, that there may be some unintentional divide between the notion of closeness in the input and the output domain of the model.
Yet another way to more ensemble variety is to vary the model itself. This is done by either varying the model’s architecture explicitly or via a Bayesian network with probabilistic dropout. In the latter case, we essentially have a model ensemble at test time due to the stochastic dropout.
Test-time data augmentation¶
Another way to uncertainty estimates is the use of test-time data augmentation. For each query point, we create an augmented set of points using some stochastic noise. In the practical examples of this notebook, we are dealing with fingerprint data. A natural way to introduce noise in such binary data is to flip bits with a small probability. This way, we obtain a set of data points for each actual query point. This, in turn, yields us a set of predictions that hopefully represents the predictive uncertainty for the query point.
Practical¶
Add short summary of what will be done in this practical section.
[2]:
from pathlib import Path
from warnings import filterwarnings
# Silence some expected warnings
filterwarnings("ignore")
import pandas as pd
from scipy.stats import norm
import numpy as np
from rdkit import Chem
from rdkit.Chem import Draw
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_context("notebook")
import tqdm
import torch
from torch import nn
from torch.utils.data import DataLoader, TensorDataset
from IPython.display import display, Markdown
# reproducibility
torch.manual_seed(0)
%matplotlib inline
[3]:
HERE = Path(".").absolute()
DATA = HERE / "data"
We re-use the predictive setting of Talktorial T022. It deals with predicting compound activity in terms of their pIC50 value to EGFR. For the prediction, we use Morgan 3 fingerprints with 2024 bits as input.
Data¶
We use the same data as in Talktorial T022. These are activities on the kinase EGFR of varying compounds found in the Chembl 25 database. The ligands are encoded using a 2048-bit Morgan 3 fingerprint.
[4]:
# Read the training and test data from pickled torch tensors.
x_train = torch.load(DATA / "x_train")
y_train = torch.load(DATA / "y_train")
x_test = torch.load(DATA / "x_test")
y_test = torch.load(DATA / "y_test")
# Create the data sets for training and testing.
training_data = TensorDataset(x_train, y_train)
test_data = TensorDataset(x_test, y_test)
# Create data loaders to iterate over training and test sets.
training_loader = DataLoader(training_data, batch_size=32)
test_loader = DataLoader(test_data, batch_size=32)
Model¶
As a model, we use a standard feed-forward network. This is similar to the one described in Talktorial T022. Here, however, we use pytorch instead of tensorflow. More details specific to Pytorch can be found in the pytorch tutorial.
[5]:
class NeuralNetwork(nn.Module):
"""A simple linear forward neural network."""
def __init__(self, p_dropout=0.05, n_hidden=512):
super(NeuralNetwork, self).__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(2048, n_hidden),
nn.ReLU(),
nn.Linear(n_hidden, n_hidden),
nn.Dropout(p_dropout),
nn.ReLU(),
nn.Linear(n_hidden, 1),
)
def forward(self, x):
x = self.flatten(x)
x = self.linear_relu_stack(x)
return x
Training¶
We now set up the pipeline of creating and training a model. With the model in place, we are ready to set up the training by defining a loss function and an optimization procedure. As a loss function, we take the mean squared error since we dealing with a regression task. For the stochastic gradient descent optimization method, we choose the Adam optimizer which is a standard choice.
[6]:
def train_loop(dataloader, model, loss_fn, optimizer=None):
"""
Run one training epoch.
Parameters
----------
dataloader : torch.utils.data.DataLoader
Data loader for the training data.
model : torch.nn.Module
The model to train.
loss_fn : function
A differentiable loss function.
optimizer : torch.optimizer.Optimizer
The optimization procedure.
"""
size = len(dataloader.dataset)
num_batches = len(dataloader)
total_loss = 0
for batch, (X, y) in enumerate(dataloader):
# Compute prediction and loss
pred = model(X)
loss = loss_fn(pred, y)
total_loss += loss.item()
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
return total_loss / num_batches
def test_loop(dataloader, model, loss_fn):
"""
Compute the test loss.
Parameters
----------
dataloader : torch.utils.data.DataLoader
Data loader for the test data.
model : torch.nn.Module
The model.
loss_fn : function
loss function.
Returns
-------
test_loss : float
test loss according to `loss_fn`.
"""
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss = 0
with torch.no_grad(): # faster evaluation
for X, y in dataloader:
pred = model(X)
test_loss += loss_fn(pred, y).item()
test_loss /= num_batches
return test_loss
To make our life simpler, when creating models, we encapsulate the model creation and training in a single function.
[7]:
def create_and_fit_model(training_loader, model_args=dict(), lr=1e-4, epochs=20, verbose=False):
"""
Create and fit a model.
Parameters
----------
training_loader : torch.utils.data.DataLoader
Data loader for the training data.
test_loader : torch.utils.data.DataLoader
Data loader for the test data.
epochs : int, optional
The number of epochs to train.
verbose: bool, optional
Print the current epoch and test loss.
Returns
-------
model: NeuralNetwork
A trained instance of `NeuralNetwork`.
"""
model = NeuralNetwork(**model_args).to("cpu")
loss_fn = torch.nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for i in range(epochs):
if verbose:
print("Epoch", i)
train_loss = train_loop(training_loader, model, loss_fn, optimizer)
if verbose:
print(f"Training loss: {train_loss:>8f} \n")
return model
Using this function, we can now create and train a predictive model.
[8]:
single_model = create_and_fit_model(training_loader, verbose=True)
Epoch 0
Training loss: 19.594438
Epoch 1
Training loss: 1.833061
Epoch 2
Training loss: 1.200345
Epoch 3
Training loss: 0.898802
Epoch 4
Training loss: 0.730146
Epoch 5
Training loss: 0.610016
Epoch 6
Training loss: 0.515054
Epoch 7
Training loss: 0.442029
Epoch 8
Training loss: 0.374235
Epoch 9
Training loss: 0.318533
Epoch 10
Training loss: 0.282265
Epoch 11
Training loss: 0.241378
Epoch 12
Training loss: 0.210448
Epoch 13
Training loss: 0.183123
Epoch 14
Training loss: 0.160263
Epoch 15
Training loss: 0.140182
Epoch 16
Training loss: 0.125900
Epoch 17
Training loss: 0.112110
Epoch 18
Training loss: 0.102701
Epoch 19
Training loss: 0.095786
Evaluation¶
For uncertainty estimation, we are not too concerned with prediction quality. Therefore, we just visually check the correlation between predictions and true values.
[9]:
pred = single_model(x_test)
sns.lmplot(
data=pd.DataFrame(
{
"model": pred.flatten().detach().numpy(),
"true value": y_test.flatten().detach().numpy(),
}
),
x="model",
y="true value",
scatter_kws={"s": 3},
)
# mean absolute error
mae_single_model = torch.abs(pred - y_test).sum().item()
# mean squared error
mse_single_model = ((pred - y_test) ** 2).sum().item()
display(
Markdown(
f"The mean absolute error is {mae_single_model:.2f} and the mean squared error is {mse_single_model:.2f}."
)
)
The mean absolute error is 758.59 and the mean squared error is 891.53.
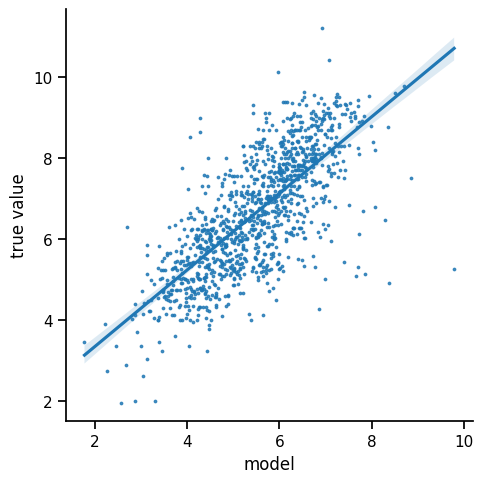
We observe a reasonable correlation between the predicted pIC50 and the measured value. It seems that our model has learned how to extract some binding affinity information from the fingerprint features.
Ensembles - Training a model multiple times¶
[10]:
ensemble_size = 20
ensemble = []
for _ in tqdm.tqdm(range(ensemble_size)):
training_data = TensorDataset(x_train, y_train)
training_loader = DataLoader(training_data, batch_size=32, shuffle=True)
model = create_and_fit_model(
training_loader,
)
ensemble.append(model)
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [03:50<00:00, 11.53s/it]
[11]:
preds = torch.stack([model(x_test) for model in ensemble]).reshape(ensemble_size, len(x_test))
We now have the predictions over all ensembles and test samples in the matrix pred. We can compute basic statistics for each point of test data, such as mean and variance. The variance or standard deviation is used as an uncertainty estimate of the prediction.
[12]:
stds = preds.std(0)
var = preds.var(0)
mean = preds.mean(0)
mae = torch.abs(mean - y_test.flatten())
total_mae = mae.sum().item()
total_mse = torch.sum((mean - y_test.flatten()) ** 2).item()
Now, it is interesting to compare the ensemble mean as a predictor to the single model predictor above.
[13]:
sns.lmplot(
pd.DataFrame(
{
"ensemble mean": mean.detach().numpy(),
"true value": y_test.flatten().detach().numpy(),
}
),
x="ensemble mean",
y="true value",
scatter_kws={"s": 3},
)
display(
Markdown(
f"The mean absolute error decreased from {mae_single_model:.2f} to {total_mae:.2f}. The mean squared error decreased from {mse_single_model:.2f} to {total_mse:.2f}."
)
)
The mean absolute error decreased from 758.59 to 727.53. The mean squared error decreased from 891.53 to 833.26.
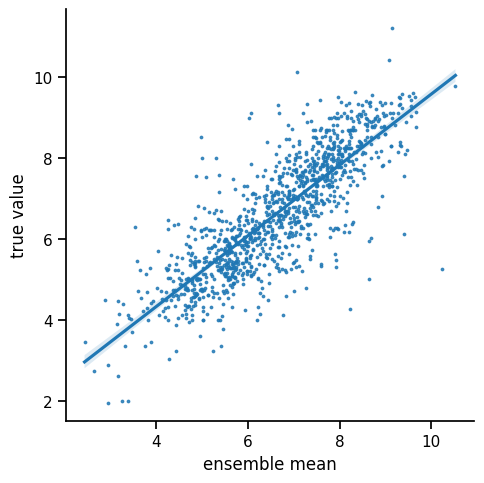
As we can see, the predictive quality on the test set increased. Originally model ensembles were introduced as a means of improving prediction quality (see Sagi and Rokach 2018). Intuitively, this is achieved by mitigating the outliers of single models.
Coverage of confidence intervals¶
For each confidence level, we can compute confidence intervals based on the standard deviations, we get out of our model ensemble. According to the definition of the confidence interval for level \(p\), the interval should cover the actual value with probability \(p\). Therefore, if we plot all hit ratios over the test for all levels in \([0,1]\), we ideally would end up with a perfect diagonal (the identity function).
[14]:
confidences = np.linspace(0, 1)
hits = []
for c in confidences:
delta = stds * norm.ppf(0.5 + c / 2) / np.sqrt(ensemble_size)
a = np.array((mean - delta < y_test.flatten()) & (mean + delta > y_test.flatten())).astype(int)
hits.append(a.sum() / len(a))
[15]:
plt.plot(confidences, hits)
plt.ylabel("coverage")
plt.xlabel("confidence")
plt.yscale("linear")
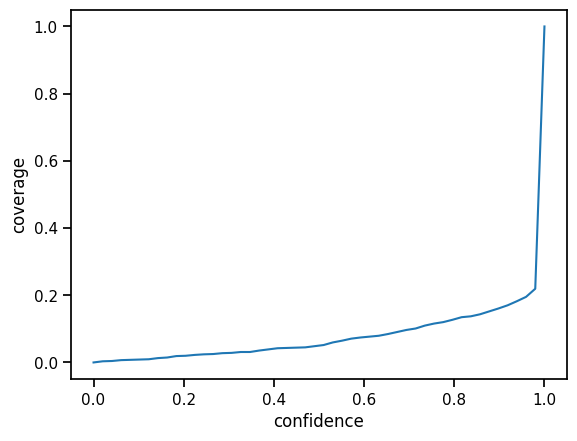
Calibration¶
First, we compute the confidence curve on a small, dedicated part of the test set. Based on the confidence curve, we compute an adjustment factor for the estimated standard deviation. This process can be refined by computing a more complex transformation. For example, one could compute such a factor for any number of bins, i.e. intervals confidences.
[16]:
num_calib = 100
preds_calibration = torch.stack([model(x_test[:num_calib]) for model in ensemble]).reshape(
ensemble_size, num_calib
)
stds_calibration = preds_calibration.std(0)
mean_calibration = preds_calibration.mean(0)
confidences = np.linspace(0, 1)
hits_calibration = []
for c in confidences:
delta = stds_calibration * norm.ppf(0.5 + c / 2) / np.sqrt(ensemble_size)
a = np.array(
(mean_calibration - delta < y_test[:num_calib].flatten())
& (mean_calibration + delta > y_test[:num_calib].flatten())
).astype(int)
hits_calibration.append(a.sum() / len(a))
calibration_adjustment = (confidences / hits_calibration)[1:-1]
calibration_adjustment = calibration_adjustment[calibration_adjustment != torch.inf].mean()
The constant calibration adjustment factor calibration_adjustment is used to compute confidence intervals. The resulting confidence curve is now much better calibrated. That means it is close to the identity function.
[17]:
hits = []
for c in confidences:
delta = (calibration_adjustment * stds * norm.ppf(0.5 + c / 2) / np.sqrt(len(ensemble)))[
num_calib:
]
a = np.array(
(mean[num_calib:] - delta < y_test[num_calib:].flatten())
& (mean[num_calib:] + delta > y_test[num_calib:].flatten())
).astype(int)
hits.append(a.sum() / len(a))
plt.plot(confidences, hits)
plt.ylabel("coverage")
plt.xlabel("confidence")
plt.yscale("linear")
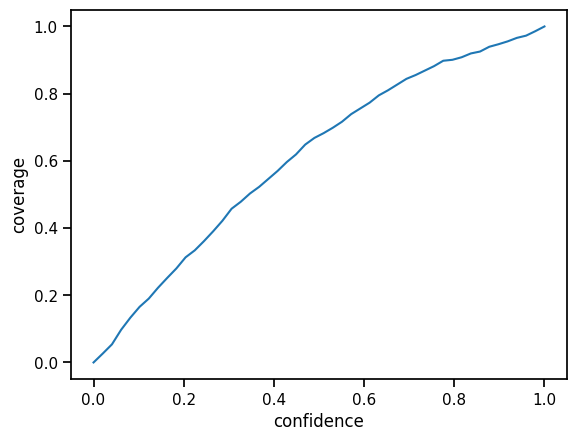
Much better! To get an even better calibration we could use more sophisticated calibration methods. For example, we could use an interval-based scheme. Especially if the curve is not consistent in over- or under-estimation of confidence, such a flexible scheme is more appropriate.
Ranking-based evaluation¶
For now, we have not really looked at how useful our ensemble is to estimate uncertainty. Ideally, poor estimations would indicate that our prediction has – at least potentially – a higher error. To assess our uncertainty prediction in this sense, we can look at confidence curves. In this ranking-based scheme, we order our estimates by decreasing uncertainty and looking at the decrease in the total absolute error for a certain number of samples. We can then compare the resulting curve with a random baseline and the ideal curve.
[18]:
idcs_mae = torch.argsort(mae, 0, descending=True).flatten()
idcs_conf = torch.argsort(stds, 0, descending=True).flatten()
plt.plot(
(total_mae - torch.cumsum(mae[idcs_conf].flatten(), 0)).detach().numpy() / total_mae,
label="ordered by est. uncertainty",
)
plt.plot(
[0, len(x_test)],
[1, 0],
label="linear decrease",
)
plt.plot(
(total_mae - torch.cumsum(mae[idcs_mae], 0)).detach().numpy() / total_mae,
"--",
label="oracle",
)
plt.legend()
plt.xlabel("sample number")
plt.ylabel("normalized MAE");
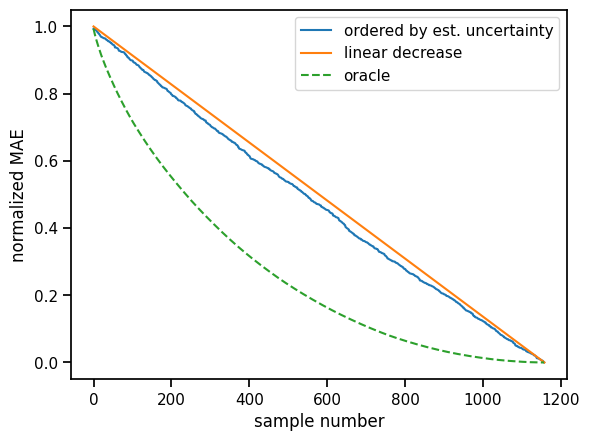
Ideally, the blue curve, i.e. our uncertainty estimates would be somewhere in between the random baseline and the ideal one. We see some improvement over the baseline, but there is room for improvement. Often, more variety is necessary for the model ensemble. Below we create more variety by bootstrapping and aggregating the training data. Another way would be, to vary the model itself in some way within the ensemble.
Bringing more variance into the ensemble¶
Often times, there is too little variance in the ensemble by just varying the order of training examples the model is exposed to. To capture the uncertainty better, we need to introduce more variety in the ensemble. There two areas in which we can introduce more ensemble variance: the data and the model.
Varying training data¶
Instead of just varying training runs, we additionally vary the training data. This is done by bootstrapping and aggregating (bagging) the data: For each run, we resample the training data with replacement to get a (likely) slightly different training set of each model. Furthermore, we use only a subset of that resampled data, likely hiding some data points for some ensemble members.
Varying model parameters¶
We can further vary model parameters across the ensemble. This variation should drive the models to learn the underlying data in different ways.
[19]:
ensemble_size = 20
ensemble_bagg = []
for _ in tqdm.tqdm(range(ensemble_size)):
idcs = torch.randint(low=0, high=int(0.75 * len(x_train)), size=(len(x_train),))
x_train_resample = x_train[idcs]
y_train_resample = y_train[idcs]
training_data = TensorDataset(x_train_resample, y_train_resample)
training_loader = DataLoader(training_data, batch_size=32)
model = create_and_fit_model(
training_loader,
model_args={
"n_hidden": 2 ** np.random.randint(5, 10),
"p_dropout": np.random.rand() * 0.1,
},
)
ensemble_bagg.append(model)
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 20/20 [01:47<00:00, 5.38s/it]
Now, that all ensembles are trained, we compute the test set predictions of all ensemble members.
[20]:
preds_bagg = torch.stack([model(x_test) for model in ensemble_bagg]).reshape(
ensemble_size, len(x_test)
)
Again, we compute basic statistics on our ensemble predictions.
[21]:
stds_bagg = preds_bagg.std(0)
var_bagg = preds_bagg.var(0)
mean_bagg = preds_bagg.mean(0)
mae_bagg = torch.abs(mean_bagg - y_test.flatten())
mse_bagg = (mean_bagg - y_test.flatten()) ** 2
Ranking-based evaluation¶
We now repeat the ranking-based evaluation from above. That is, we plot the confidence curve against the constantly decreasing baseline and the optimal solution (Oracle).
[22]:
idcs_mae_bagg = torch.argsort(mae_bagg, 0, descending=True).flatten()
idcs_conf_bagg = torch.argsort(stds_bagg, 0, descending=True).flatten()
total_error = mae_bagg.sum().item()
plt.plot(
(total_error - torch.cumsum(mae_bagg[idcs_conf_bagg].flatten(), 0)).detach().numpy()
/ total_error,
label="ensemble with more variance",
)
plt.plot(
(total_mae - torch.cumsum(mae[idcs_conf].flatten(), 0)).detach().numpy() / total_mae,
label="standard ensemble",
)
plt.plot(
[0, len(x_test)],
[1, 0],
label="linear decrease",
)
plt.plot(
(total_error - torch.cumsum(mae_bagg[idcs_mae_bagg], 0)).detach().numpy() / total_error,
"--",
label="oracle",
)
plt.legend()
plt.xlabel("sample number")
plt.ylabel("normalized MAE");
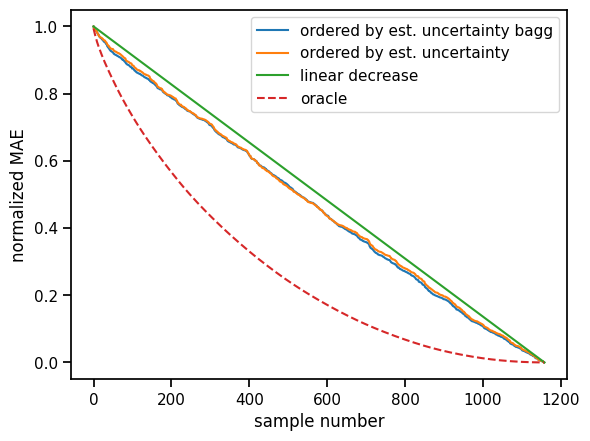
We observe a consistent improvement over the baseline. This means the uncertainty estimates help us in getting an impression of estimate quality. Poorer estimates are more likely to have a higher estimated uncertainty than the better ones.
Test-time data augmentation¶
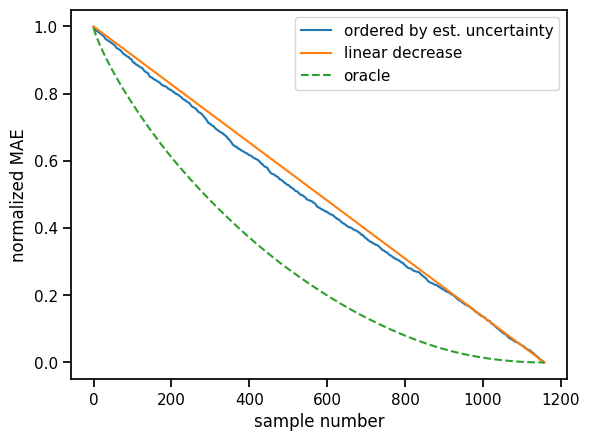
Finally, we showcase test-time data augmentation. The benefit here is that it can be applied to pretty much any model. The basic idea is to sample around each test sample. This set of similar samples should provide information on the local variability. Large variability is assumed to imply higher uncertainty.
In the context of fingerprints, we are dealing with bitstrings of fixed length. To sample around each test sample, we augment each test sample with N_AUG additional samples. In each sample and position, we introduce a mutation, i.e. a bit flip with a fixed probability (here \(p=0.01\)).
[23]:
N_AUG = 200
x_test_aug = torch.repeat_interleave(x_test, N_AUG, dim=0)
mutations = torch.rand_like(x_test_aug) < 0.01
x_test_aug = torch.logical_xor(mutations, x_test_aug)
x_test_aug = torch.tensor(x_test_aug, dtype=torch.float32)
pred = single_model(x_test_aug)
pred = pred.reshape(-1, N_AUG, 1)
((pred.mean(1) - y_test) ** 2).sum()
stds_aug = pred.std(1)
mae_aug = torch.abs(pred.mean(1) - y_test)
torch.cumsum(mae_aug[torch.argsort(stds_aug, 0, descending=True).flatten()].flatten(), 0)
idcs_mae = torch.argsort(mae_aug, 0, descending=True).flatten()
idcs_conf = torch.argsort(stds_aug, 0, descending=True).flatten()
total_err = mae_aug.sum().item()
plt.plot(
(total_err - torch.cumsum(mae_aug[idcs_conf].flatten(), 0)).detach().numpy() / total_err,
label="ordered by est. uncertainty",
)
plt.plot(
[0, len(x_test)],
[1, 0],
label="linear decrease",
)
plt.plot(
(total_err - torch.cumsum(mae_aug[idcs_mae].flatten(), 0)).detach().numpy() / total_err,
"--",
label="oracle",
)
plt.legend()
plt.xlabel("sample number")
plt.ylabel("normalized MAE");
Discussion¶
The field of uncertainty estimation is highly relevant to almost all machine learning applications and computer-aided drug discovery is no exception. Thus, currently, there is significant effort put into improving methodologies. Many issues such as explainability or objective evaluation protocols for uncertainty quantification remain to be addressed. However, if predictions are to be used in the real world, uncertainty cannot be ignored.
Quiz¶
What are the main sources of uncertainty?
How could we get a model ensemble without training many models?
In which scenarios can uncertainty estimation fail?